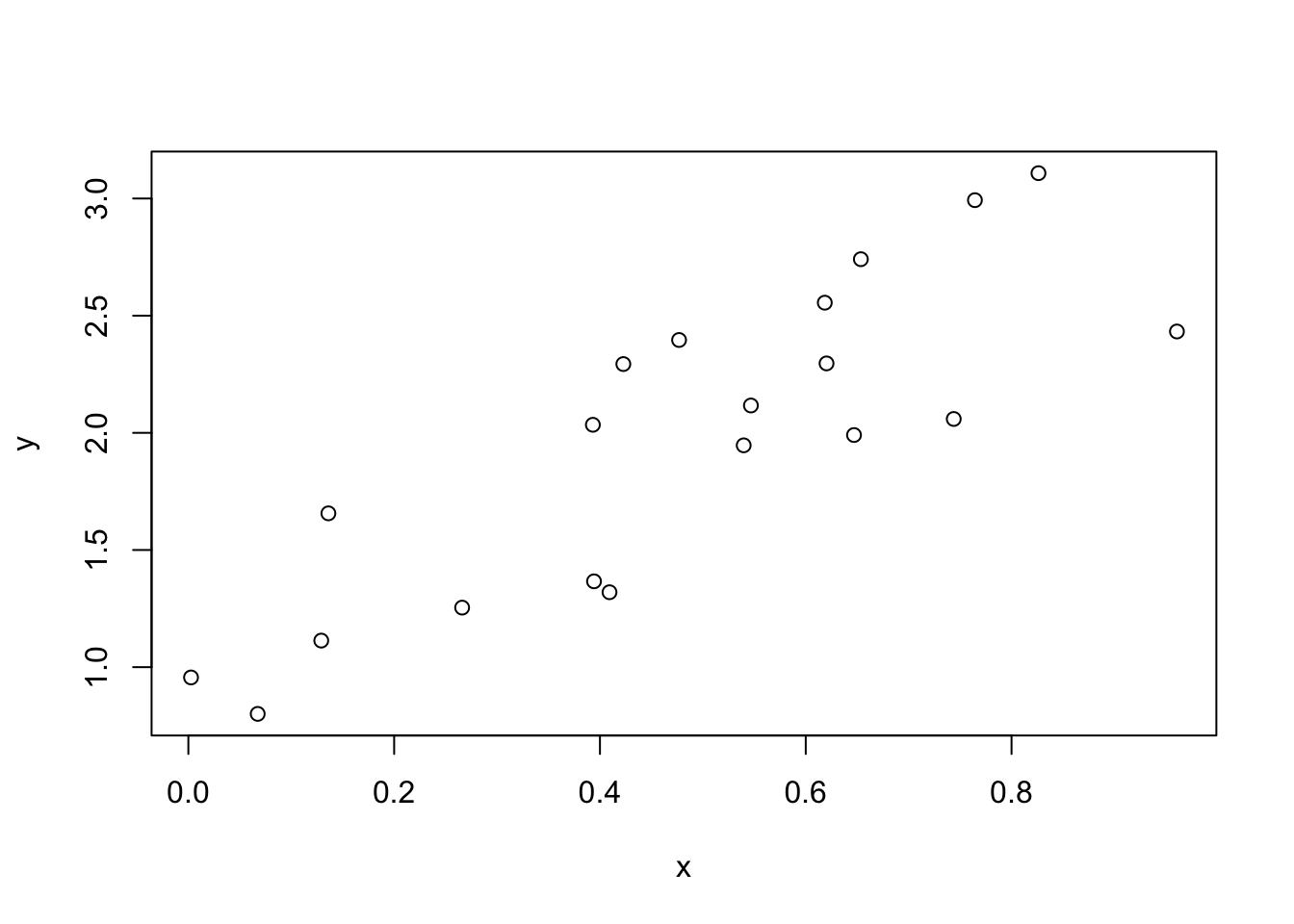
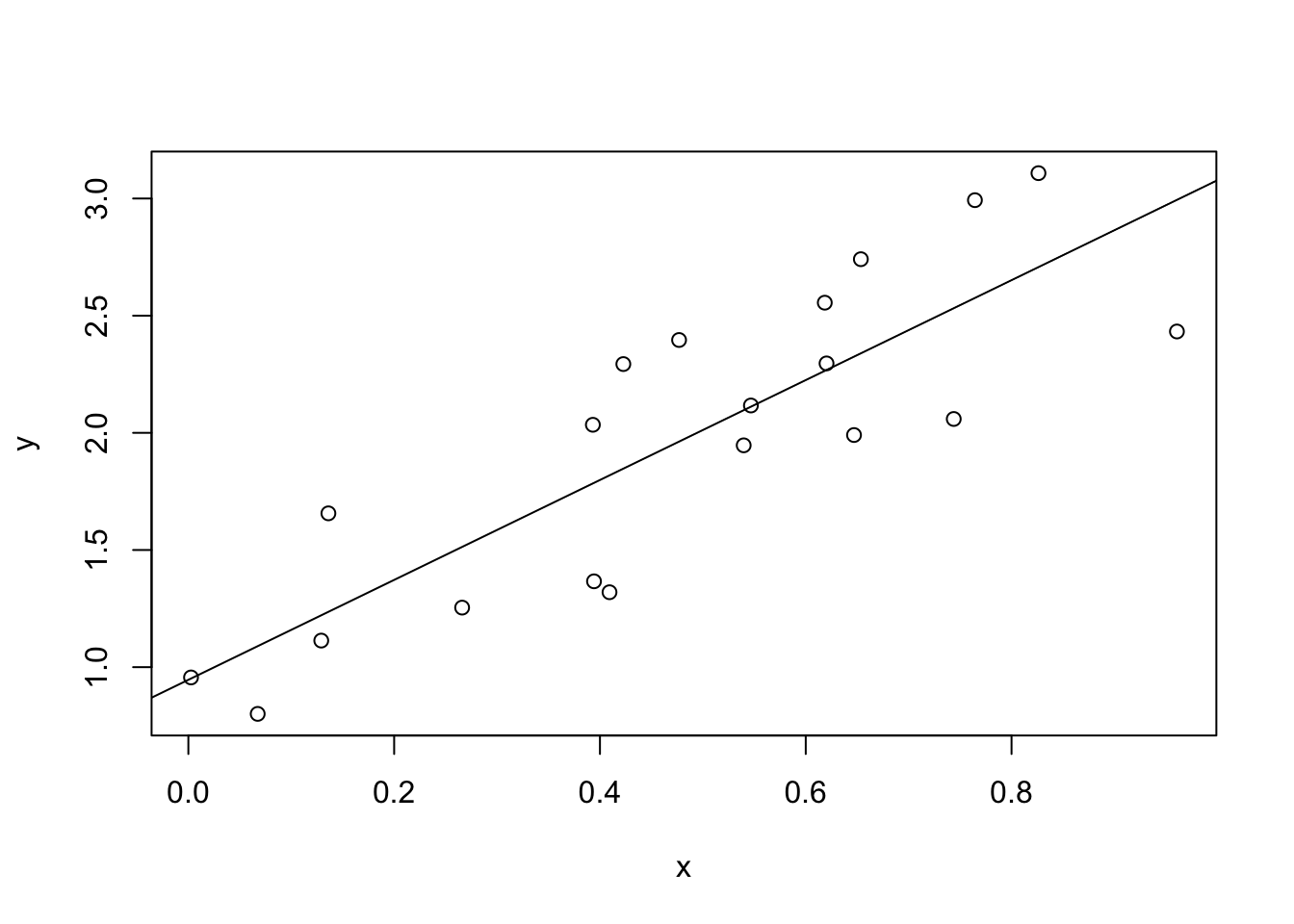
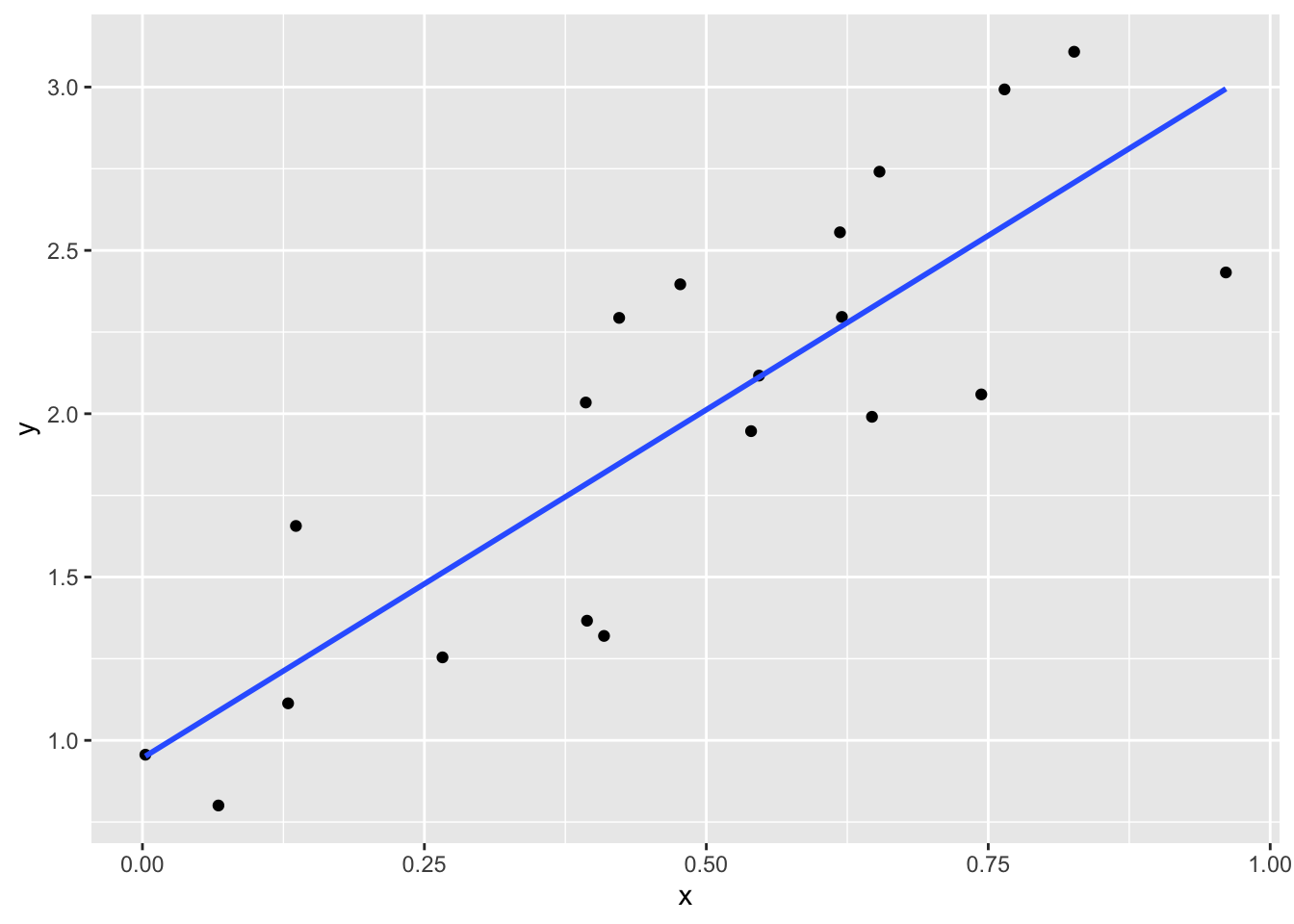
For Windows users, install Rtools for using some R packages (e.g., ggplot2).
R creates an interactive environment for you to play with data and statistical models. If you have no exposure to computer-based statistical computing before, I dare say that learning R will be the most valuable experience for you in this course.
After installing R and RStudio on your PC/Mac, you can play with the following scripts in RStudio. You can run R Scripts line by line using the shortcut Ctrl-Enter/Command-Enter (or maybe Shift-Enter depending on your local machine).
2 Use R as a calculator
# In R, comments start with # symbol# This line will not be run
num =3num +2
[1] 5
## vectorx =c(2, 7, 5) # Here "c" is short for combinex
[1] 2 7 5
## a vector (sequence) from 1 to 5y =seq(1, 5)y
[1] 1 2 3 4 5
## a sequence from 1 to 5 with step=2seq(1, 5, 2) # seq(from=1, to=5, by=2)
[1] 1 3 5
?seqx + y
Warning in x + y: longer object length is not a multiple of shorter object
length
[1] 3 9 8 6 12
options(warn =-1) # hide warningsx / y
[1] 2.000000 3.500000 1.666667 0.500000 1.400000
## extracting sub-vector (also called subsetting)x[1]